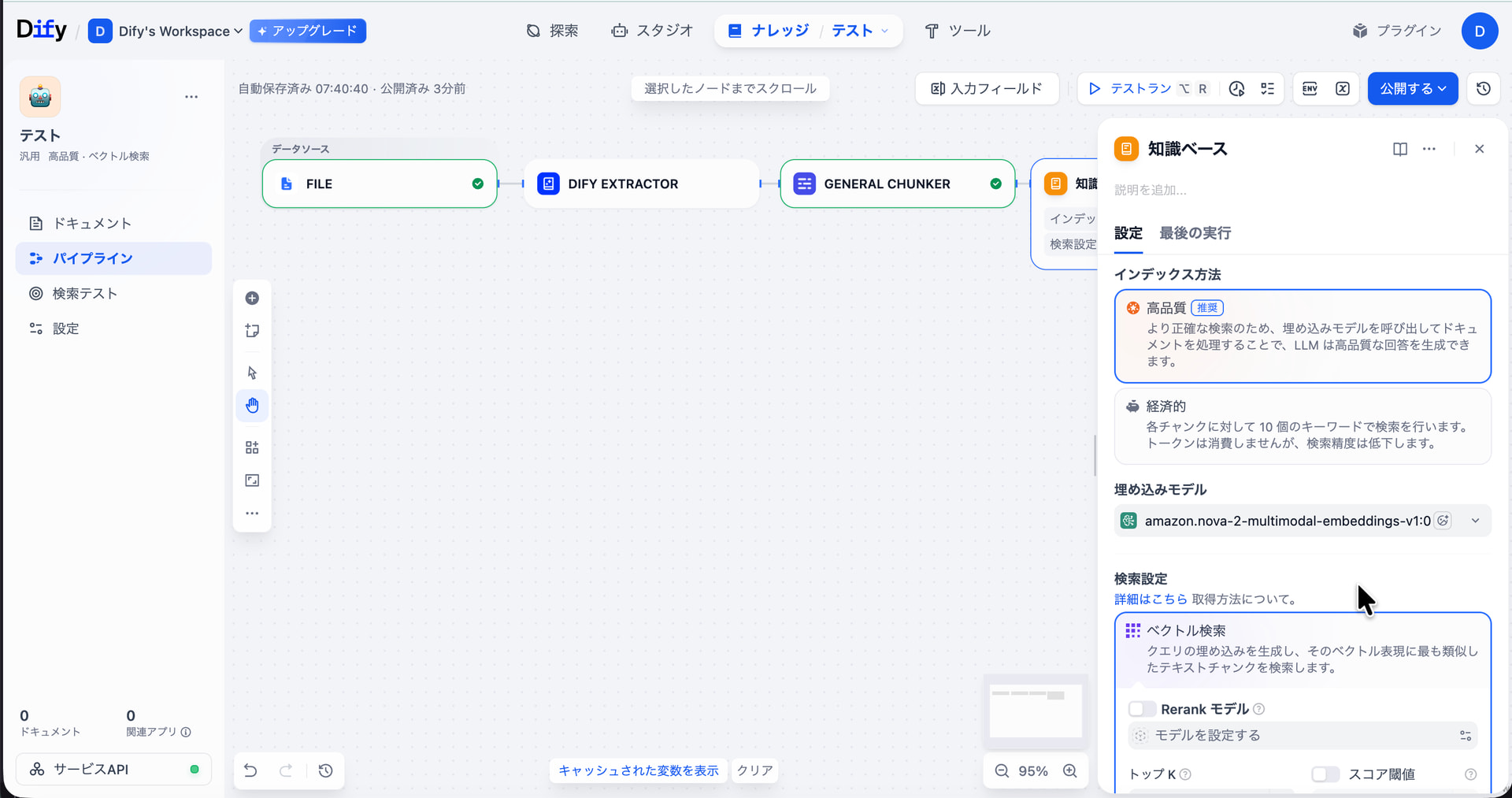
I am trying to build a multimodal RAG using nova-2-multimodal-embeddings-v1:0.
When I processed a PDF file containing both images and text with Dify Extractor, I was only able to obtain textual information.
Based on the following documentation, I believe that I need to use Doc Extractor instead of Dify Extractor:
https://docs.dify.ai/en/use-dify/knowledge/knowledge-pipeline/knowledge-pipeline-orchestration#doc-extractor
However, I cannot find Doc Extractor in my environment at https://cloud.dify.ai/.
Where is this Data Processing Tool located?