在“代码执行”节点中无法单独关联 input_file, rules_file, stock_file,并怀疑与 userinput.files 有关。请求提供正确映射变量或处理遗留字段的官方方法。

@Dify_Forum_Helper 简单帮我追问一下更多信息,待会发给技术支持。
我这边先帮你向 TA 补充追问一些关键信息,方便技术支持后面排查:
@tiantian0920 想跟你确认几件事,麻烦有空补充一下哈:
-
当前使用的 Dify 版本号是多少?
- 如果是自建 Docker,可以看
docker-compose.yml里langgenius/dify的 tag - 或者在「设置 → 关于」里看版本号截图
- 如果是自建 Docker,可以看
-
你的输入字段配置具体是怎样的?
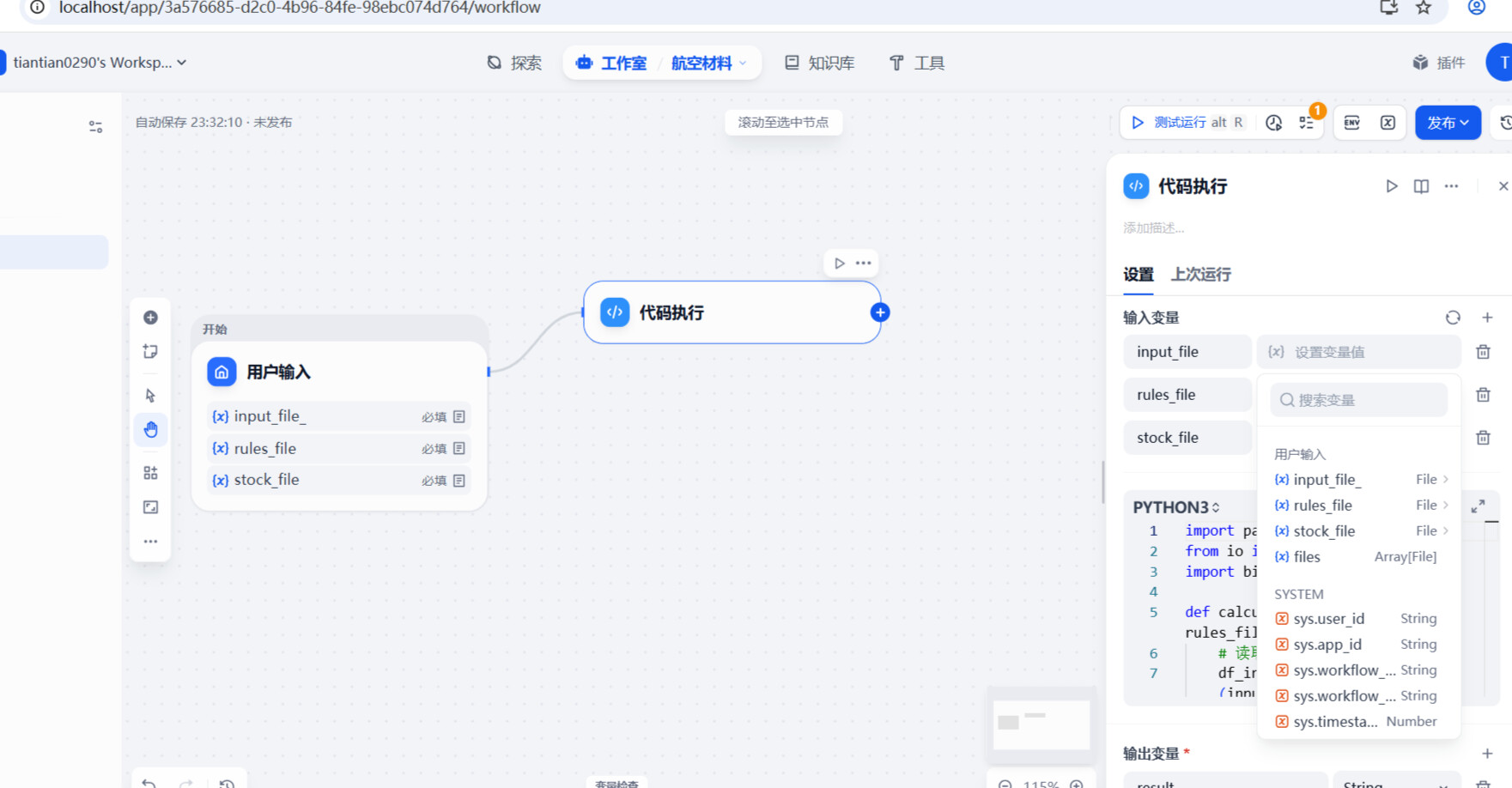
从截图看,开始节点有 3 个文件输入:input_file_(注意这里尾部是_还是没有?)rules_filestock_file
代码执行节点右侧「输入变量」里,也建了同名的 3 个变量。想确认下:- 这 3 个变量的类型是否都设置为
File? - 代码里是通过
variables["input_file"]/variables["rules_file"]/variables["stock_file"]这样的方式读取的吗?可以贴一小段关键代码(脱敏即可)。
-
现在具体遇到的问题表现是:
- 在代码执行节点的「输入变量」那里,下拉列表里能不能分别选到
input_file_/rules_file/stock_file? - 还是说三个变量都只能映射到同一个
userinput.files(LEGACY)? - 运行时实际拿到的是:
- 全部都为空?
- 还是 3 个变量拿到的其实是同一个文件?
麻烦可以贴一张代码执行节点的「输入变量映射」配置截图(右侧那块),以及一张运行记录里变量实际值的截图。
- 在代码执行节点的「输入变量」那里,下拉列表里能不能分别选到
-
是否是从旧版本拷贝/导入的工作流?
因为你这里显示了userinput.files (LEGACY):- 这个字段通常是旧版本的「用户上传文件集合」遗留字段
- 想确认:这个工作流是新建的,还是从很早之前的工作流复制/导入过来的?
- 如果是旧流复制过来,开始节点里是否还有隐藏或已删除但没完全清理掉的旧文件字段?
-
你期望的行为是怎样的?
是想要:- 用户一次上传 3 个不同用途的文件(输入文件 / 规则表 / 库存表),
- 然后在代码里能分别拿到:
input_file # 用户输入文件 rules_file # 规则表 stock_file # 库存表
对吗?还是希望它们最后合并成一个数组再处理?
我这边也会把这些问题点整理给技术支持:
- 当前 UI 同时存在:单独文件变量(
input_file/rules_file/stock_file)和userinput.files (LEGACY),需要确认:- 现在的正确映射方式:是否推荐完全不用
userinput.files,而是直接让代码执行节点 1:1 绑定到每个文件字段? - 对于已经存在
userinput.files的老工作流,官方推荐的迁移/清理方式 是什么(比如:重新新建开始节点字段 + 重新绑定 code 节点,还是有系统级迁移逻辑)? LEGACY字段是否可能干扰到新字段的自动映射或运行结果?
- 现在的正确映射方式:是否推荐完全不用
等你把上面的信息和截图补充一下,我会一起转给技术支持,方便他们给出「正确的变量映射方式」以及「如何处理/迁移 userinput.files (LEGACY)」的官方建议。

先把目前能确认的信息和建议整理给你,方便你和技术支持对齐:
1. 版本 & 代码情况梳理
- 你当前版本:v4.57.0
- 代码里是函数签名形式:
def calculate_blank(input_file, rules_file, stock_file):
df_input = pd.read_excel(input_file)
df_rules = pd.read_excel(rules_file)
df_stock = pd.read_excel(stock_file)
说明你的预期是:在「代码执行」节点中,直接拿到 3 个 单独的文件变量。
2. 目前 Dify 的“推荐思路”(结合版本和 UI 变化)
在 4.x 以后的版本里,文件输入已经从早期的统一 userinput.files,演进成「每个输入字段一个独立的 File 变量」:
-
开始节点:
input_file_(注意你截图里似乎有个尾巴_)rules_filestock_file
-
代码执行节点右侧「输入变量」面板里,你应该这样配置(核心是 1:1 手动绑定,而不是再用
userinput.files):- 新建 3 个输入变量,类型都设为 File:
input_file→ 映射到「开始节点 / input_file_」rules_file→ 映射到「开始节点 / rules_file」stock_file→ 映射到「开始节点 / stock_file」
然后你的代码就可以直接用你贴出来的那种函数签名。
- 新建 3 个输入变量,类型都设为 File:
userinput.files (LEGACY)一般是老版本统一文件集合的兼容字段,在新设计里并不再推荐使用,尤其是像你这样需要区分多个业务含义文件的场景。
3. 建议你现在重点自查这几项
-
变量名是否完全一致
- 开始节点字段叫
input_file_,而你函数里是input_file:- 如果右侧代码节点输入变量叫
input_file,但它实际映射到的开始节点字段是input_file_,这是允许的(名字不要求完全相同), - 但要确认:右侧「输入变量 → input_file」里,下拉选中的是
开始·input_file_,而不是选成了userinput.files (LEGACY)。
- 如果右侧代码节点输入变量叫
- 开始节点字段叫
-
每个变量都手动绑定到具体字段
- 在代码执行节点右侧:
input_file这一行的来源一定要选:用户输入 · input_file_rules_file→ 选:用户输入 · rules_filestock_file→ 选:用户输入 · stock_file
- 如果下拉里还能看到
userinput.files (LEGACY),保持不选,不配置任何变量指向它。
- 在代码执行节点右侧:
-
运行时检查变量值类型
在代码开头先打印一下,确认拿到的是文件对象(而不是 None 或字符串):import pandas as pd def calculate_blank(input_file, rules_file, stock_file): print("DEBUG input_file =", input_file) print("DEBUG rules_file =", rules_file) print("DEBUG stock_file =", stock_file) df_input = pd.read_excel(input_file) df_rules = pd.read_excel(rules_file) df_stock = pd.read_excel(stock_file) ...然后在「上次运行」里看 3 个变量的值,确认是否分别对应你上传的 3 个 Excel。
4. 关于 userinput.files (LEGACY) 的处理建议
在目前能看到的信息下,可以先按下面的“保守做法”处理:
-
新建 / 重建开始节点字段(如果这个流程是从老版本复制、导入来的):
- 确认开始节点的 3 个输入字段确实是新版「文件」类型(
File),而不是历史遗留的那种合并字段。 - 如果一开始是从旧流复制,可以考虑:
- 新增 3 个新的 File 字段(比如
input_file_new等), - 在代码节点重新映射,确认没问题后,再删除旧字段和
userinput.files (LEGACY)。
- 新增 3 个新的 File 字段(比如
- 确认开始节点的 3 个输入字段确实是新版「文件」类型(
-
在整个流程里不再使用
userinput.files:- 不在任何节点引用它;
- 不再依赖它做文件分发;
- 真正都从单独的 File 字段读取。
后续如果官方给出更明确的“如何清理 / 迁移 LEGACY 字段”的说明,可以再按照官方步骤做最后一次整理;但在此之前,“不用它 + 全部走显式字段”通常是最安全的做法。
5. 建议你再补几张截图,方便技术支持精确判断
你现在已经给了函数代码,非常有用。再补两张的话,会更容易定位问题:
-
代码执行节点右侧「输入变量」的完整截图
- 让人能看到:
input_file/rules_file/stock_file三行各自映射到哪个来源字段。
- 让人能看到:
-
「上次运行」→ 查看该节点的输入数据截图
- 展示一下这三个变量在运行时的实际值(是否为空 / 是否变成同一个文件)。
我会基于你补的这两张,再帮你把“当前行为”和“预期行为”的差异总结成要点,转给技术支持,重点说明:
- 在 v4.57.0 上,新老字段混用时的行为;
- 是否存在 bug(比如映射 UI 允许选,但运行时都指向同一个文件或为空);
- 能否把
userinput.files (LEGACY)完全隐藏或一键迁移。
如果你方便,也可以顺手说明一下:这个工作流是新建的,还是从老版本复制/导入的? 这个信息也会影响官方的排查方向。
3、在代码执行节点的「输入变量」那里,下拉列表里不能分别选到 input_file_ / rules_file / stock_file,只能点击
![]() 可以选择,
可以选择,
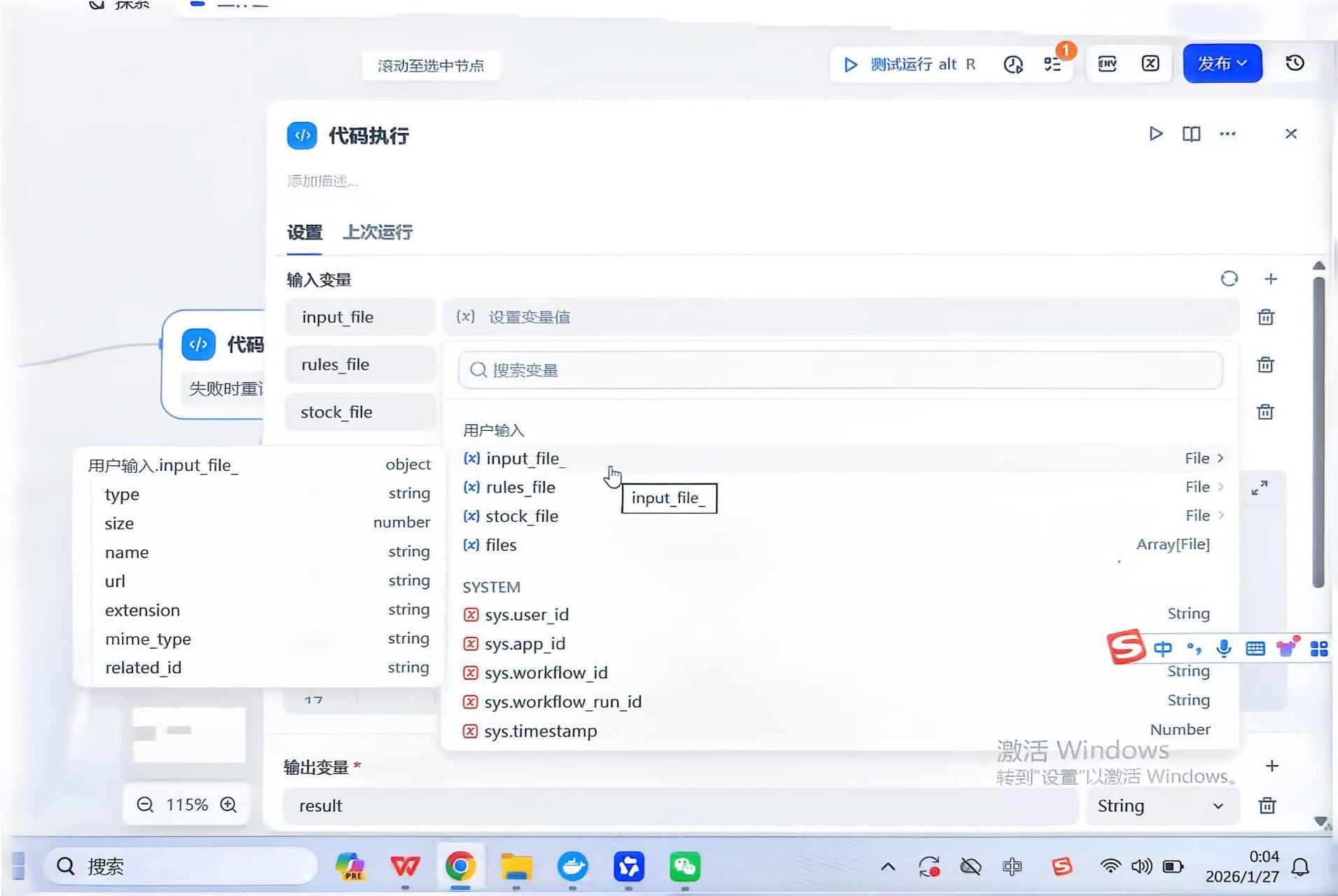
4、我是购买技术人员远程安装的,不是从旧版本拷贝/导入的工作流,是新建的
5、想要用户一次上传 3 个不同用途的文件(输入文件 / 规则表 / 库存表),
-
然后在代码里能分别拿到:
input_file # 用户输入文件 rules_file # 规则表 stock_file # 库存表
直接让代码执行节点 1:1 绑定到每个文件字段,不想要userinput.files,不然在设置对应的标量值时,,无法选择对应的文件